gpt-oss-recipes
综合介绍
gpt-oss-recipes 是由Hugging Face社区维护的一个开源项目,它提供了一系列专门用于OpenAI最新开源GPT模型(gpt-oss-20b和gpt-oss-120b)的Python脚本和Jupyter Notebook。这个代码库的核心目标是为开发者和研究人员提供一套现成的工具,用于演示和实现对这些大型语言模型的高级优化和微调技术。具体来说,该项目包含了实现张量并行(Tensor Parallelism)、Flash Attention、专家并行(Expert Parallelism)等多种推理优化技术的脚本,能够显著提升模型在推理时的效率和吞吐量。此外,项目还提供了监督微调(Supervised Fine-Tuning, SFT)的脚本,并同时支持全参数微调和低显存占用的LoRA(Low-Rank Adaptation)微调方法。通过这些配方,用户可以更容易地在自己的硬件设施上部署、运行和定制这些强大的开源模型。
功能列表
- 模型支持: 支持OpenAI的
gpt-oss-20b(200亿参数)和gpt-oss-120b(1200亿参数)两款大型语言模型。 - 张量并行推理: 提供
generate_tp.py脚本,允许将模型切分到多个GPU上进行并行计算,以运行超出单卡显存容量的大模型。 - Flash Attention优化: 提供
generate_flash_attention.py脚本,集成了Flash Attention技术,在进行张量并行的同时,进一步提升推理速度和效率。 - 连续批处理 (Continuous Batching): 通过
generate_tp_continuous_batching.py脚本,支持连续批处理,优化GPU利用率,提高多用户场景下的总吞吐量。 - 集成优化:
generate_all.py脚本集成了专家并行、张量并行和Flash Attention等所有优化技术,以达到最佳推理性能。 - 监督微调 (SFT):
sft.py脚本用于对模型进行微调。 - 全参数微调: 支持使用多GPU(例如8卡节点)进行完整的模型参数微调,以最大程度地适配新数据。
- LoRA微调: 支持在单张GPU上使用LoRA技术进行轻量化微调,这种方法仅训练少量可注入的参数,大幅降低了硬件门槛和训练成本。
使用帮助
这个代码库提供了一系列脚本,帮助你在自己的硬件上运行和微tuning OpenAI的开源GPT模型。以下是详细的操作流程。
1. 环境安装
首先,你需要一个干净的Python环境。推荐使用uv来创建虚拟环境,这可以加快安装速度。
步骤一:创建并激活虚拟环境打开终端,运行以下命令。这里以Python 3.11为例。
uv venv gpt-oss --python 3.11
source gpt-oss/bin/activate
接着,升级pip工具。
uv pip install --upgrade pip```
**步骤二:安装PyTorch和Triton**
`gpt-oss-recipes`依赖特定版本的PyTorch和Triton内核。请使用以下命令进行安装,注意这里指定了针对CUDA 12.8的测试版PyTorch下载地址。
```bash
uv pip install torch==2.8.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/test/cu128
```如果你的GPU硬件支持MXFP4量化格式(例如H100),安装Triton内核可以获得更好的性能。
```bash
uv pip install git+https://github.com/triton-lang/triton.git@main#subdirectory=python/triton_kernels
步骤三:安装其他依赖最后,安装代码库requirements.txt文件中列出的所有其他依赖项。
uv pip install -r requirements.txt
2. 如何选择模型
在运行任何脚本之前,你需要在脚本文件中指定要使用的模型。所有生成脚本(generate_*.py)和微调脚本(sft.py)的顶部都有一个模型配置区域。
打开你想要运行的脚本文件,例如generate_tp.py,找到以下代码:
# Model configuration - uncomment the model size you want to use
model_path = "openai/gpt-oss-120b" # 120B model (default)
# model_path = "openai/gpt-oss-20b" # 20B model - uncomment this line and comment the line above
默认配置是120B模型。如果你想使用20B模型,请注释掉120b这一行,并取消20b那行的注释。脚本会根据你选择的模型自动配置合适的设备映射和设置。
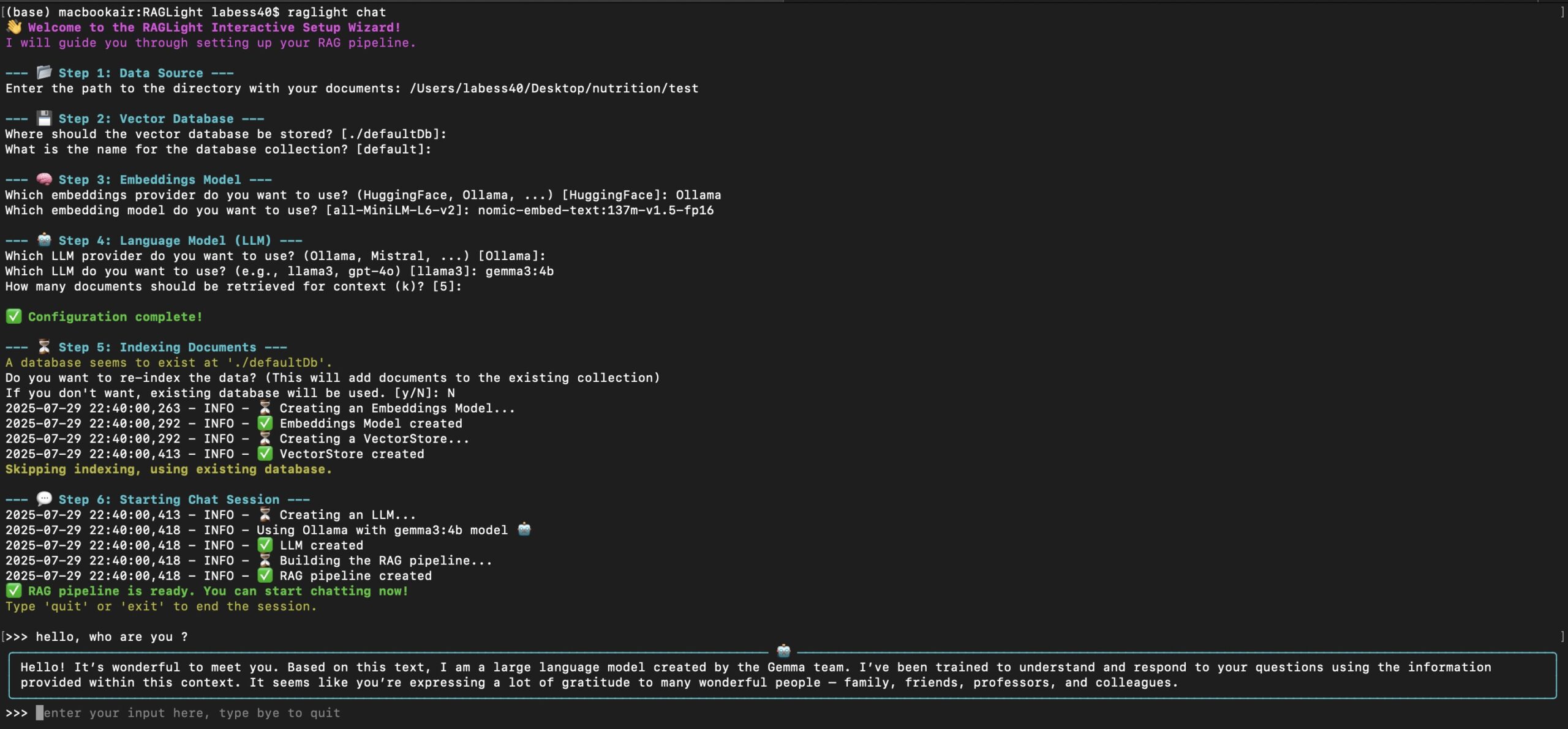
3. 如何进行推理
推理脚本用于生成文本。根据你的硬件情况选择不同的脚本。
单GPU或单节点多GPU运行:选择一个优化脚本,例如使用Flash Attention的generate_flash_attention.py,然后直接用Python运行。
python generate_flash_attention.py
分布式(多节点)运行:如果你需要在多个节点上进行分布式推理,需要使用torchrun启动器。你需要指定每个节点的GPU数量(nproc_per_node)。
torchrun --nproc_per_node=4 generate_tp.py
这里的x代表每个节点的GPU数量,例如4。
4. 如何进行训练(微调)
代码库支持两种微调方式:全参数微调和LoRA微调。
方式一:全参数微调 (Full-parameter training)这种方式会更新模型的所有参数,效果最好,但需要非常高的硬件配置(例如一个含8个H100 GPU的节点)。
你需要使用accelerate工具来启动训练。配置文件zero3.yaml定义了分布式训练策略(ZeRO Stage 3),可以有效降低显存消耗。
# 使用标准Eager Attention进行训练
accelerate launch --config_file zero3.yaml sft.py --config configs/sft_full.yaml
# 如果硬件支持,可以使用FlashAttention3进一步提速
accelerate launch --config_file zero3.yaml sft.py --config configs/sft_full.yaml --attn_implementation kernels-community/vllm-flash-attn3
方式二:LoRA微调 (LoRA training)LoRA是一种参数高效的微调方法,它只训练一小部分新增的参数,而原始模型权重保持不变。这种方法极大地降低了硬件要求,通常在单张消费级或专业级GPU上即可完成。
直接使用Python运行sft.py脚本,并指定LoRA的配置文件。
python sft.py --config configs/sft_lora.yaml
如何使用自定义数据或调整参数:你可以直接修改configs目录下的sft_full.yaml或sft_lora.yaml文件来更改训练参数,例如学习率、训练轮次、数据集名称等。
另一种更灵活的方式是通过命令行参数覆盖配置文件中的设置。例如,要更换数据集,可以运行:
accelerate launch --config_file zero3.yaml \
sft.py --config sft_full.yaml \
--dataset_name "your-huggingface-dataset-name"
这样就可以使用你自己的数据集(需要符合脚本要求的数据格式)来进行微调。
应用场景
- 学术研究与模型优化研究人员可以利用
gpt-oss-recipes深入探索和比较不同的并行计算策略(如张量并行、专家并行)和注意力机制(如Flash Attention)对大语言模型性能的影响。这些脚本提供了一个标准化的实验平台,让他们可以复现结果并验证新的优化算法。 - 特定领域模型的定制化微调企业和开发者可以将通用的
gpt-oss模型通过微调适配到特定业务场景,例如金融、医疗、法律或客服等。 使用sft.py脚本和LoRA方法,可以用较低的成本在自有数据上训练模型,使其掌握特定领域的知识和语言风格,同时保护数据隐私。 - 高效推理服务的生产部署对于需要将大模型集成到线上应用中的场景,性能至关重要。
gpt-oss-recipes中的推理脚本(如generate_all.py)展示了如何组合使用多种优化技术,以实现高吞吐量和低延迟的推理服务。开发者可以此为基础,构建可扩展、高效率的模型API服务。
QA
- 这个代码库是做什么的?
gpt-oss-recipes是一个脚本和代码的集合,由Hugging Face社区提供,旨在帮助开发者更轻松地在自己的硬件上对OpenAI的开源GPT模型(20B和120B)进行性能优化和监督微调。 - 支持哪些模型?目前主要支持OpenAI的两个开源模型:
openai/gpt-oss-20b和openai/gpt-oss-120b。 - 全参数微调和LoRA微调有什么区别?全参数微调会更新模型的所有权重,效果潜力更大,但需要极高的计算资源(如多张H100 GPU)。LoRA是一种轻量化微调技术,它冻结原始模型参数,只训练少量附加参数,因此在单张GPU上即可完成,极大降低了硬件门槛。
- 我需要什么样的硬件来运行这些脚本?
gpt-oss-20b模型:使用MXFP4量化后大约需要16GB显存,适合在单张高端消费级GPU(如RTX 4090)或专业卡上运行。gpt-oss-120b模型:至少需要60GB显存,通常需要H100级别的计算卡或多GPU并行设置才能运行。
- 如何使用我自己的数据集进行微调?你可以在
sft.py脚本运行时,通过--dataset_name参数指定你在Hugging Face Hub上的数据集名称。另外,你需要确保你的数据集格式与脚本所期望的输入格式一致。你也可以直接修改YAML配置文件来指定数据集信息。